신경망 학습
위 발표는 강현님이 보내주신 발표 자료를 기반으로 참고사항을 추가해 각색하여 만들었습니다. 오류가 있는 부분은 저에게 말씀해주시고, 질문 및 기타 관련 사항 역시, 강현님 혹은 저에게 말씀해 주시면 됩니다.
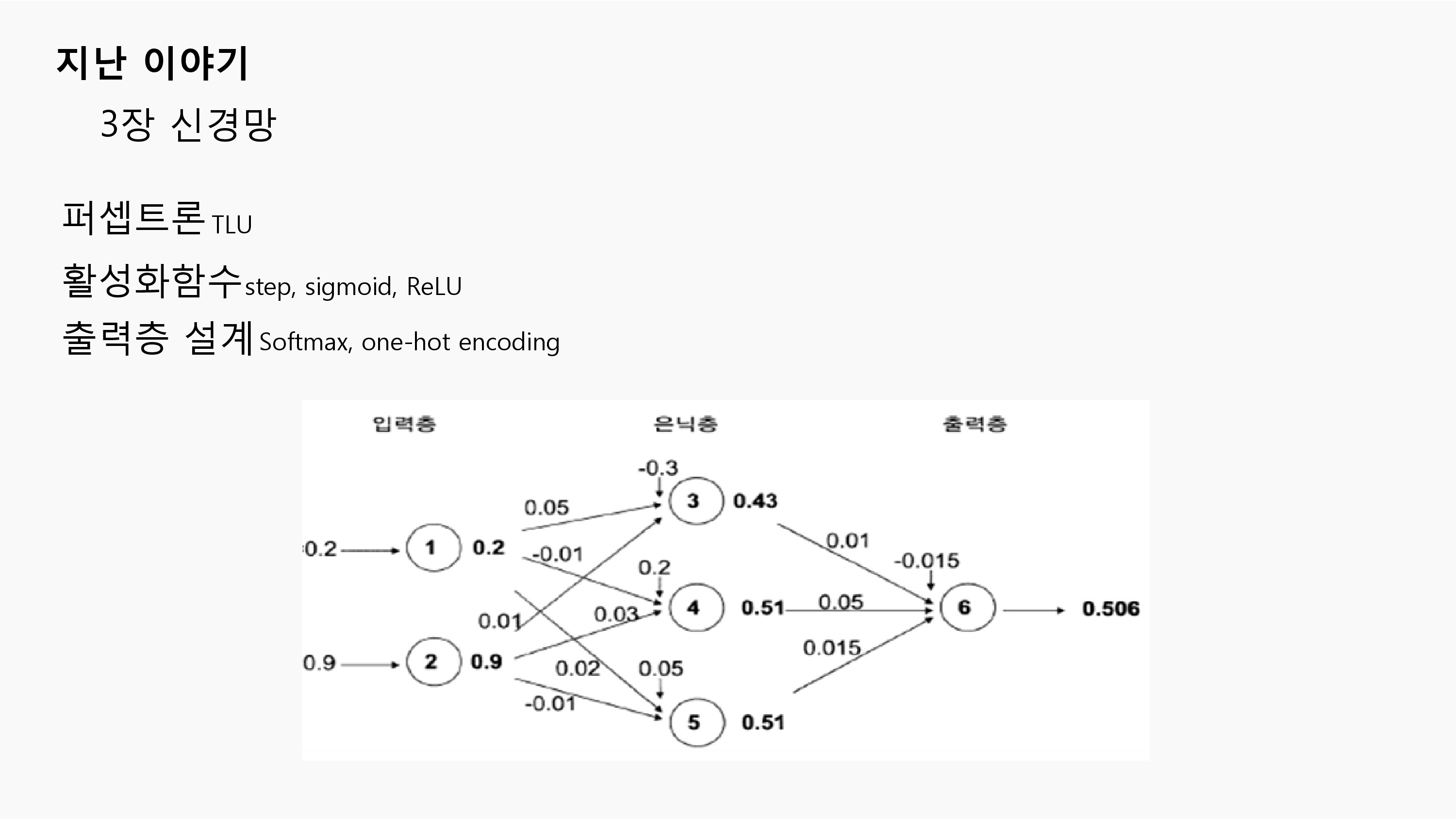
지난시간에 우리는 퍼셉트론과 신경망에 대해 알아보았습니다.
실제 뇌신경 속의 뉴런 구조에서 착안을 얻은 퍼셉트론과 유의미한 의미를 전달하는 활성화 함수, 출력층을 설계하는 softmax함수등을 알아보았습니다.

이번 신경망 학습에서 언급되는 Gradient Descent(경사하강법)는 60년 발표한 Delta Rule을 기본으로 하는 이론입니다. 이미 62년에도 Delta Rule과 다층 신경망이 제시되었지만 수학적으로 제시된 학습 방법의 부재로 인공지능의 첫번째 겨울이 오게 됩니다. Gradient Descent는 연결주의(Connectionism)의 마스터 알고리즘이라 하는 역전파 알고리즘이 사용되는데 이번 4장에서 소개가 되었습니다.
머신러닝에서 Delta Rule이란, 단일층 신경망에서 입력의 가중치를 인공 뉴런으로 업데이트하는 경사하강 학습 규칙입니다.
 4장에서는 크게 2가지로, 손실함수와 경사하강법(GD)에 대해 다루게 됩니다.
4장에서는 크게 2가지로, 손실함수와 경사하강법(GD)에 대해 다루게 됩니다.

머신러닝에서의 학습이란, 신경망 모델이 우리가 원하는 결과를 반환할 수 있도록 각 파라미터를 적당한 값으로 갱신하는 것을 의미합니다.
소프트맥스 함수는 출력층에 들어온 값을 (0,1)사이의 값으로 사상시키고 이를 다 합치면 1이 되는 이산확률분포를 만들어 줍니다.
 학습이 요구되는 것은 우리의 신경망 모델이 실제값을 제대로 추론해내야 하기 때문입니다. 때문에 현재 상태의 추론값과 실제값의 차이로 학습의 상태를 판단할 수 있는 지표가 필요합니다.
학습이 요구되는 것은 우리의 신경망 모델이 실제값을 제대로 추론해내야 하기 때문입니다. 때문에 현재 상태의 추론값과 실제값의 차이로 학습의 상태를 판단할 수 있는 지표가 필요합니다.
손실함수는 MSE(평균제곱오차 : Mean Squared Error)와 CEE(교차 엔트로피 : Cross Entropy Error)를 많이 사용합니다.

평균제곱오차는 추론값과 실제값의 차이의 제곱을 평균한 값이 됩니다.
이러한 평균제곱오차는 쉬운 착안에서 가져온 만큼 자주 사용되는 손실합수입니다.
 이런 평균제곱오차는 취급하기 쉬운 장점이 있지만 Sigmoid함수를 목적함수로 받을 때 모양이 convex하지 못하여 경사하강법을 적용하지 못하는 문제를 지니고 있습니다.
이런 평균제곱오차는 취급하기 쉬운 장점이 있지만 Sigmoid함수를 목적함수로 받을 때 모양이 convex하지 못하여 경사하강법을 적용하지 못하는 문제를 지니고 있습니다.
또한 Sigmoid함수는 MSE에 넣어서 GD를 사용하면 학습속도가 느려지는 효과가 생기며 이것은 비용적 측면까지 이어지므로 경계해야 합니다.
이러한 문제는 같은 이유에서 이후 vanishing gradient descent(sigmoid 함수 혹은 tanh 함수는 최대 미분값이 1(sigmoid는 1/4)이고 양 끝점으로 갈수록 0이 되는 형태로, 옛날에 적용된 미분값이 시간이 지나며 0으로 수렴하게 되어 더이상 기억하지 못하는 것 : ReLU를 쓰는 이유, 링크 참고) 문제에 영향을 주게 됩니다.
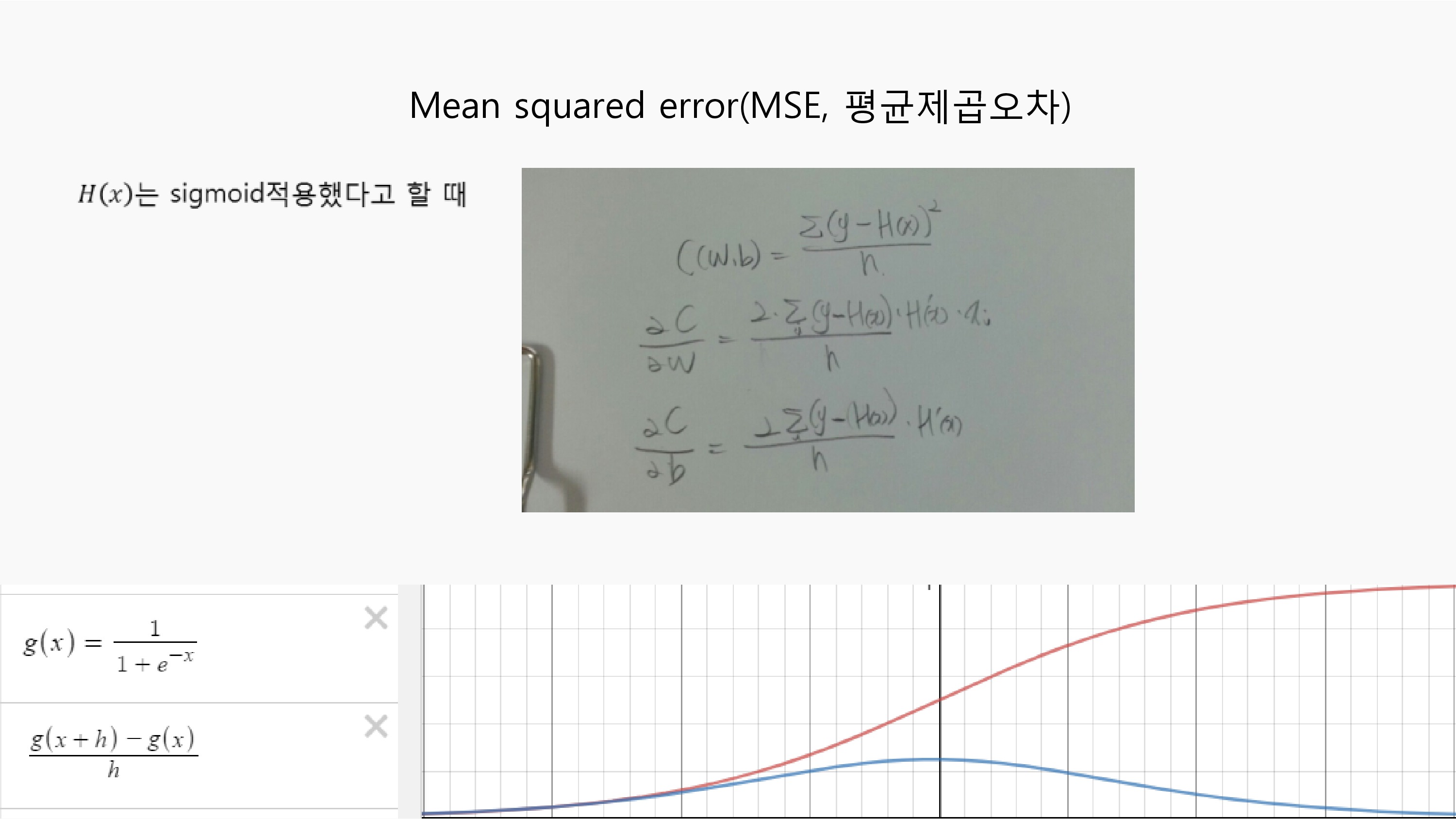 H(x)가 시그모이드 함수(빨강색)라고 할 때, MSE의 목적함수를 Wb에 대하여 편미분을 수행하면 H(x)의 미분값이 남아있게 되고(파랑색) 이것은 H(x)의 도함수가 0에서 멀어지는 값이 들어갈수록 급속도로 작아지는 값입니다.
H(x)가 시그모이드 함수(빨강색)라고 할 때, MSE의 목적함수를 Wb에 대하여 편미분을 수행하면 H(x)의 미분값이 남아있게 되고(파랑색) 이것은 H(x)의 도함수가 0에서 멀어지는 값이 들어갈수록 급속도로 작아지는 값입니다.
이 값은 오차 (y-H(x))가 크더라도 무시하는 경향을 주기 때문에 학습에 속도를 더디게 합니다.
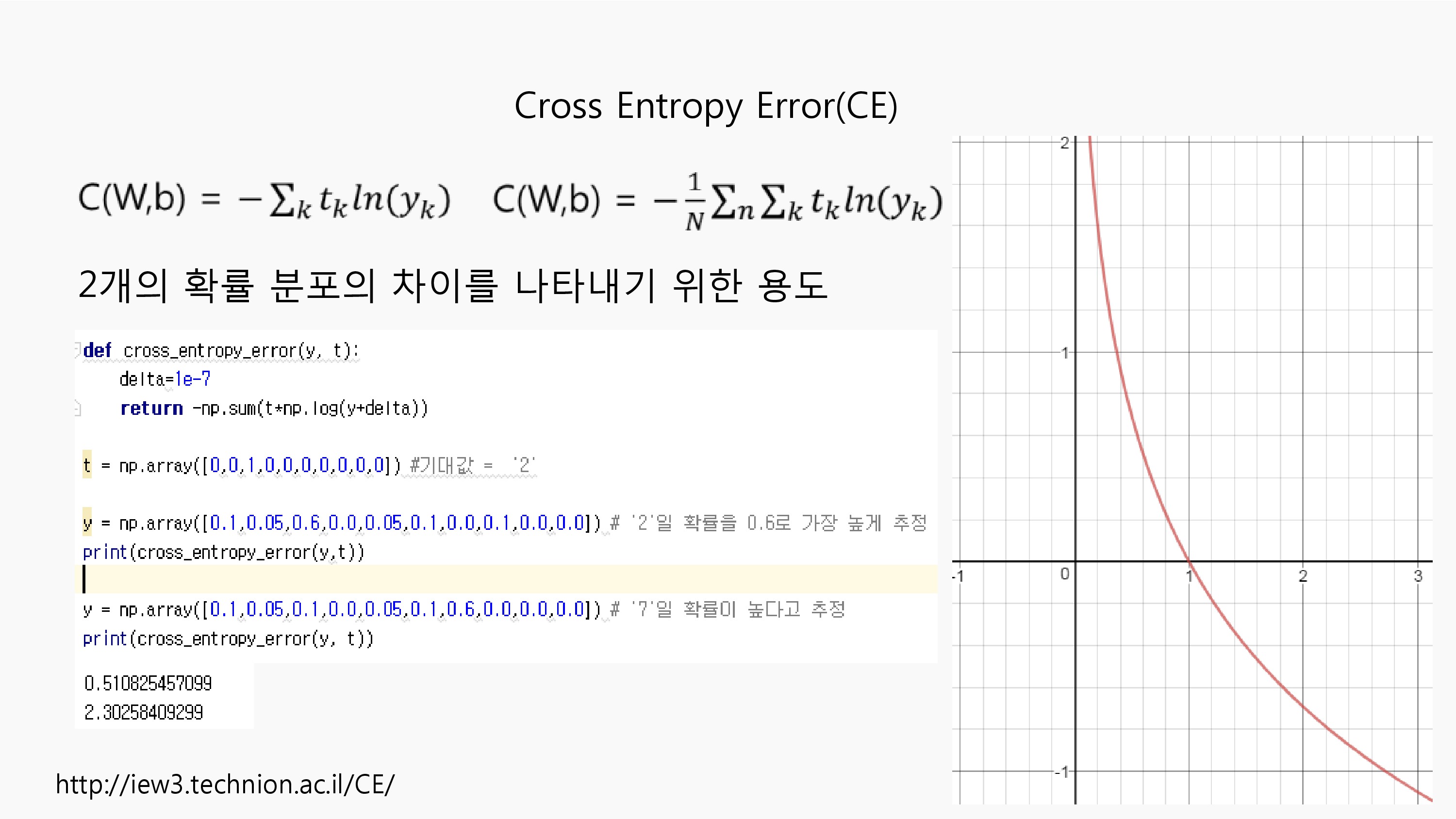
Cross Entropy는 이를 제목으로한 원서가 존재할 정도로 역사와 활용 분야가 넓은 다용성 메소드입니다.두 개의 확률 분포 차이를 비교하기 위한 지표로 사용되는데 우리의 손실함수 목표와 부합합니다.대신 반드시 비교할 실제값을 softmax 함수의 결과처럼 이산확률분포로 만들어 줘야 하는데 이것이 one-hot인코딩이 됩니다.이때, 실제값이 0인 성분들의 합은 무시되고, 1인 성분만 그것을 추론한 성분과 비교되는데 -log(x) 함수에 넣어 비교하게 됩니다. 추론값이 1이면 에러는 0, 추론값이 0에 가까워지면 무한에 가까운 값을 반환하기 때문에 손실함수로서 적합합니다.

Sigmoid함수를 목적함수로 한 Cross Entropy 손실함수를 W와 b에 대하여 미분하게 되면 Sigmoid의 미분값의 영향이 남지 않으므로 MSE에 비해 학습에 속도가 더 좋습니다.
반면, MSE와 CEE의 성능은 비슷한 결과를 보인다고 합니다.
/*
<참고> : 굳이 안보셔도 크게 상관없을 듯 합니다;
Entropy라는 단어는 상당히 많은 곳에서 사용된다.(열역학에서도 사용된다.) 보안계열에서는 Random Number Generator에서 사용되기도 한다. 이런 Entropy는 이곳에선 어떤 정보를 전달하는데 필요한 최소 비트 수를 말하며(단위가 비트) 불확실성(uncertainly)을 의미하기도 한다. 즉, 불확실성이 높을수록 entropy는 증가한다.
A,B,C,D라는 attribute가 있는 가설 공간(Hypothesis Space)에서 Decision Tree를 만들 때, A의 확률, ~A의 확률과 같이 분류(Classification)하여 Tree를 만들면 만들 수 있는 Tree의 가짓수는 매우 많다. 그러나, A를 나눌 때, 그 하단에 올 확률이 모두 True다 라고 하면 Entropy(불확실성)은 0이 되고, 이로써 information gain은 커지게 된다. ( 예를 들어, 비가 올 확률(A)이 True일때, 땅이 젖을 확률(B)도 모두 True가 된다고 하자. 그러면 Tree를 나눌때, Entropy를 이용한 계산이 제일 낮은 A를 상위 노드(부모)로 하고 B를 하위노드(자식)으로 둔다면, C와 D까지 이어지는 Tree가 더욱 간단해진다. )
우리가 Solution을 찾아가는 방향은 언제나 가능한 Simple하게 구하는 것을 원칙으로 한다.(Ockham`s razor)
Decision Tree 는 supervised Learning에 있어서, training set으로 function을 찾는 것이 쉽지 않을 때 사용할 수 있는 방법이다.( Decision tree induction is one of the simplest and yet most successful forms of machine learning. )
시각적이고 명시적으로 의사 결정 과정과 결정된 의사를 보여주며 어떤 항목에 대한 관측값과 목표값을 연결시켜주는 예측 모델에서 분류를 예측하기 위해 사용한다.
각 variable의 entropy를 구하는 공식은 -PlogP의 합이다.
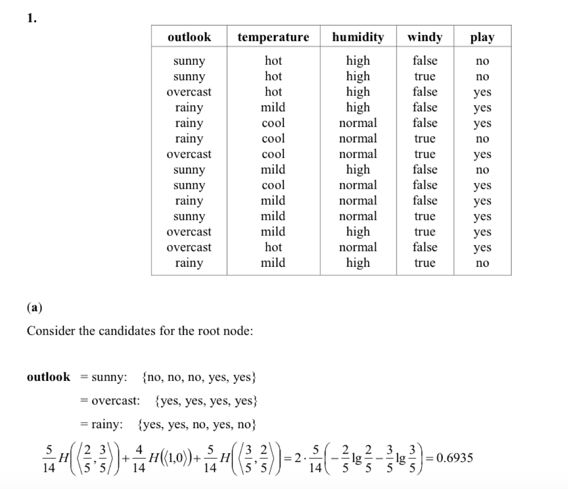
위 이미지에서 앞선 4가지 (outlook ~ windy)는 attribute고 play가 class다.
아래 식은 outlook에 대한 엔트로피와 레코드 수로 root node를 찾는 과정이다.
outlook의 속성으로 sunny, overcast, rainy가 있고, play의 boolean으로 설정된 결과에 따라
(해당갯수/전체갯수)H(<True Prob., False Prob.>)
를 계산하여, 모두 다 더한다. ( 엔트로피를 계산한 후 노드의 속한 레코드의 개수를 가중치로 하여 엔트로피를 평균한 값 )
이 계산의 H함수는 앞서 말한 entropy공식으로 -PlogP를 계산하는 것이다.
( 앞서, Entropy에 대한 설명에 추가로, 예를 들어 True, False가 반반의 확률이라면, -1/2log(1/2) - 1/2log(1/2)가 되어 1이 된다. 그러나 모두 True나 False 라면 -1log(1)-0log(0)이 되어 0이 된다. 즉, 0이 되면 자식노드로 한개를 만들면 되는 것이고 이에 따라 entropy가 0에 가까울수록 compact한 그래프가 만들어진다. )
모든 attribute에 대해 위 과정을 수행하고, 그 값들의 최소값(choose the attribute that minimizes the remaining information needed.)이 되는 attribute가 root node가 된다. 이후 자식 노드를 제작하는 과정도 root node 이외의 다른 variable에 대해 같은 방법으로 진행한다.
여기서 최소값이 되는 이유는 information gain이 최대가 되기 때문이다.
information gain(정보이득)은 어떤 속성을 선택함으로 인해서 데이터를 더 잘 구분하게 되는 것으로, information gain이 클수록 데이터의 구분이 더욱 좋다는 의미다.
이 식은 [ 상위노드entropy - 각 하위노드의 엔트로피를 계산한 후 노드의 속한 레코드의 개수를 가중치로 하여 엔트로피를 평균한 값 ]이다.
위 outlook을 계산해보면,
부모노드의 Entropy : 0.940
하위노드( sunny ) Entropy : 0.971 가중치 : 5/14
하위노드(overcast) Entropy : 0 가중치 : 4/14
하위토드( rainy ) Entropy : 0.971 가중치 : 5/14
Information Gain : 0.246

위와 같이 계산할 수 있다.
그러나 information gain도 가끔 outleading 할 수 있다.
예를 들어, 학번과 같은 attribute의 경우, 모두 각각 unique한 값을 가진다.
이럴 때, information gain은 maximum이 되어 버린다.
그래서 대신해서 쓰는 것이 gain ratio다.
이는 일종의 information gain에 정규화를 적용하는 개념이다. 따라서 다음 공식을 따른다.

split info는 n이 많아질 수록 증가한다. 따라서 정규화의 내용이 들어맞게 된다.
마지막으로 outlook의 root level에서 gain ratio를 구해보자.

root entropy = 0.9403
outlook information gain = 0.9403 - 0.6935
split Info = 1.5774
(참고 자료)
http://www.inf.unibz.it/dis/teaching/DWDM/slides2011/lesson5-Classification-2.pdf
http://eehoeskrap.tistory.com/13
http://ai-times.tistory.com/161
http://m.blog.naver.com/laonple/220554852626
*/

학습이 얼마나 요구되는지에 대한 지표가 나왔고 이를 반복적으로 적용하여 W,b를 갱신해야 합니다. 이를 위한 방법으로 Gradient Descent를 사용합니다.
Gradient(기울기)의 의미처럼 현재위치의 기울기를 보고 다음 갱신방향으로 W를 조정하는 것이 기본 착안입니다.

교재에 있는 f(x,y)=x**2+y**2 함수를 (3,4) 위치에서 GD를 사용하여 지역 최소값을 찾아가는 프로그램입니다.
위 소스는 예제로서 데이터 하나당 100번 갱신했지만 실제 신경망 모델을 학습시킬 때는 전체 데이터(1 epoch)당 한번의 가중치 갱신을 하는 것이 우선 기본 GD의 학습 과정입니다.

GD는 현재위치의 기울기로부터 지역적인 최소값을 찾아가는 방식이기 때문에 전체 최적해를 보장하지 못하는 것을 염두에 두어야 합니다.
목적함수가 Convex하더라도 고원에 정체되거나 안정점에 머무를 수 있고, 학습률이 너무 작으면 학습속도가 느리고, 학습률이 너무 크면 해를 찾지 못하고 발산할 수 있습니다.
곡률에 따라 zigzag로 움직여서 학습이 느릴 수 있습니다.
이를 해결하기 위해 Line Search 혹은 수렴 정도에 따른 학습률 조정등을 적용합니다.
Q) 단순히 Gradient Descant 외에 ADAM이라는 것을 쓰던데 그것은 무엇인가?
최근에 자주 쓰이며, 학습 속도 개선을 위해 개량된 Stochastic Gradient Descent 중 하나.
(참고자료)
http://aikorea.org/cs231n/neural-networks-3/
http://keunwoochoi.blogspot.kr/2016/12/stochastic-gradient-descent.html
<참고>

위 그래프와 같이 목적함수는 다양한 상태에 머무를 수 있다.
언제나 global maximum이 되면 좋겠지만, shoulder와 같은 정체구간 혹은 local maximum에 빠지기 쉽다.
이를 해결하기 위한 방안을 몇가지 소개하고자 한다.
흔히, gradient ascent/descent search 라는 경사상승/하강법은 hill climbing search라고도 한다.
이런 hill climbing search의 개념은 결국 현재보다 더 나은 지점이 어딘지를 찾는 것이다.
단순히, 지금보다 더 나은 지점을 찾는 것이기 때문에 똑같이 local maximum에 빠질 수 있다.(상당히, greedy한 접근이다.)
따라서 같은 hill climbing 이지만 어떻게 하냐에 따라서 몇가지 방법이 나뉜다.
stochastic hill climbing : chooses at random from among the uphill moves with probability proportional to steepness.
경사에 비례하는 확률로 랜덤하게 선택하는 방법
First-choice(simple) hill climbing : generates successors randomly until one is found that is better than the current state.
현재보다 나은 상태를 발견할 때까지 무작위로 생성
Random-restart hill climbing : Conducts a series of hill-climbing searches from randomly henerated initial states.
초기상태를 무작위로 선정
이제, hill climbing이 아닌 다른 방법을 소개하겠다.
Simulated Annealing Search : 쉽게 말해 조금 손해보는 것은 고려하고 state를 찾는 것.
Local Beam Search : 처음 정한 state가 너무 independent하므로 k개를 정하여 시작하는 것.
Genetic Algorithm이 Stochastic Local Beam Search의 하나이다.
(Chromosome design -> initialize -> Selection -> Crossover -> Mutation -> update generation ->go to selection)
k 개로 시작한 유전배열 중 선택된 것을 교배, 돌연변이과정(Heuristic)을 겪고, 세대를 거듭해 답을 찾아가는 것.
Line Search(직선탐색법) : 최적화 기법에서 스텝(step)의 크기를 결정하는 방법, 이동하고자 하는 방향을 따라서 실제 함수값의 변화(기울기)를 미리 살펴본 후에 (함수값을 최소화하도록) 이동할 양을 결정하는 방식.
등이 있다.
(참고자료)