딥러닝 발표
위 발표는 이예진님이 보내주신 발표자료와 강현님께서 정리해주신 자료로 만들었습니다. 오류가 있는 부분은 저에게 말씀해주시고, 질문 및 기타 관련 사항은 이예진님 혹은 저에게 말씀해 주시면 됩니다.
참고자료 : 밑바닥부터 시작하는 딥러닝, 김성훈 교수님 강의

퍼셉트론의 기원은 사람의 뉴런입니다. 뉴런도 여러 개의 Input이 있는 모습을 확인 할 수 있고, 출력도 여러 개의 출력이 나가는 형태를 확인할 수 있습니다.
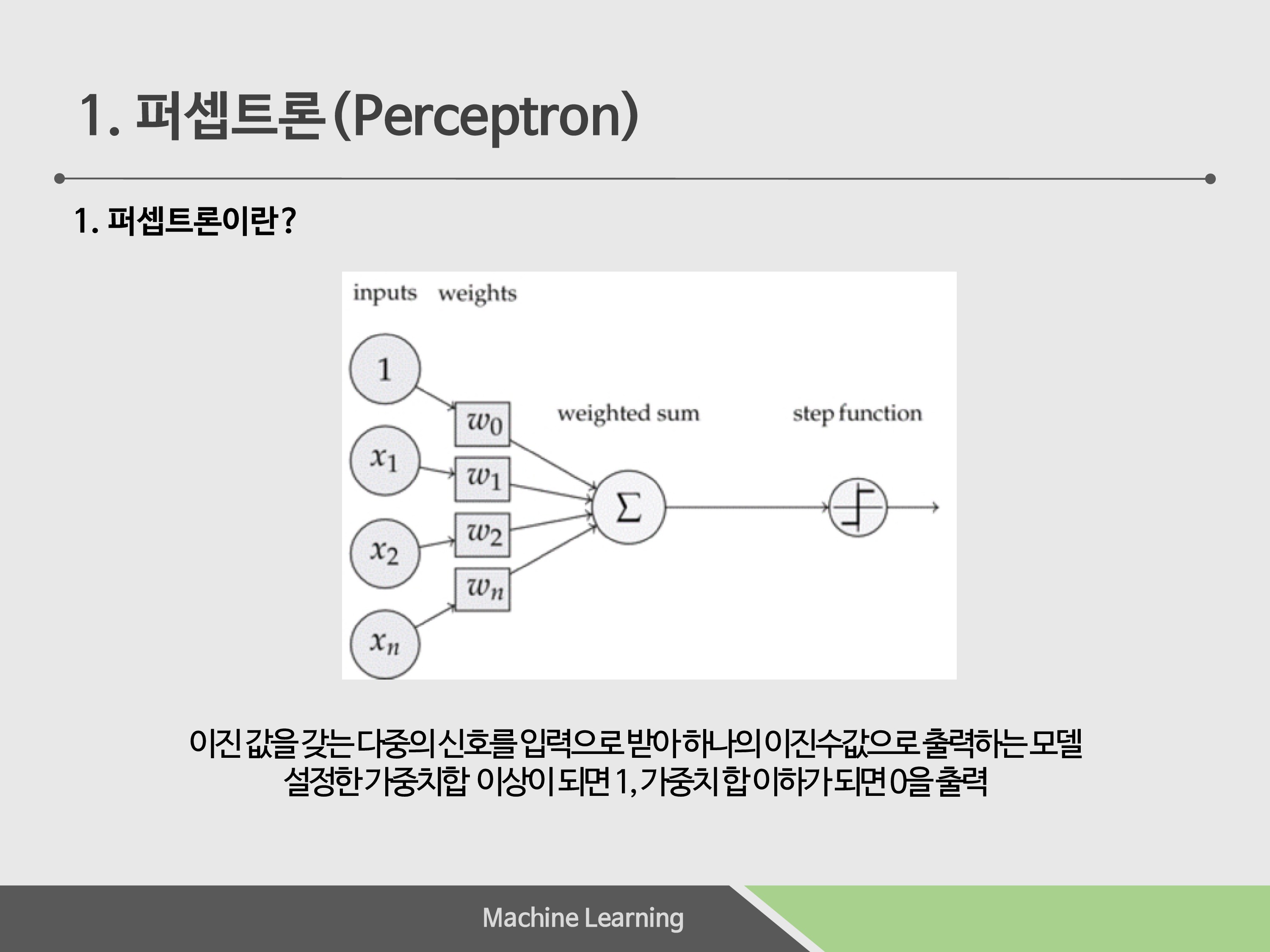
퍼셉트론은 이진 값을 갖는 다중의 입력을 받아서 일정의 가중치 합 이상이 되면 1을 출력, 일정 가중치 합 이하가 되면 0을 출력하는 것입니다.

퍼셉트론의 매개변수는 총 2개입니다. Bias, 즉 편향과 가중치입니다. 이 두 가지의 값에 따라 출력값이 바뀌게 됩니다.
그리고, 이미지에서 보이는 step function, 즉 활성화 함수는 퍼셉트론에서는 계단함수로 차용했습니다. 최종적으로는 이 step function을 거쳐 값이 출력되게 됩니다.
결과적으로 ‘학습’이란, 적절하게 매개변수 값을 정하는 절차를 뜻합니다.
Q1. 임계값을 편향이라 보는 이유는?
Q2. 편향이 필요한 이유는 뭘까?
편향은 이후 딥러닝(DNN)에 가서는 언급이 없음. 퍼셉트론 모델에서는 학습된 가중치값과 독립변수의 선형결합의 결과를 조정해주기 위해 bias가 필요하나 이후 DNN에서 미분 및 정규화 등이 적용됨으로 상수 값이 의미가 없어지는 부분이 아닐까 한다.
(조금 더 공부해보며 알아가도록 하자)

퍼셉트론을 논리회로를 예로 들어 설명하겠습니다. 학습은 이 가중치를 조절하는 것이지만 편의를 위해 편향과 가중치를 고정하였습니다.
And 게이트를 예로 들면, W1 = 0.5, W2 = 0.5, 요구하는가중치의합이 0.7이라면 ,
W1*X1 + W2*X2 = theta
가 되는데, 이 경우에는 입력이 1, 1이어야 theta의 값을 넘길 수 있기 때문에, 진리표처럼 출력이 (1, 1)이 되어야 Output이 1이 됩니다. 다른 게이트도 이와 같이 가중치를 잘 조절하면 구현이 가능합니다.
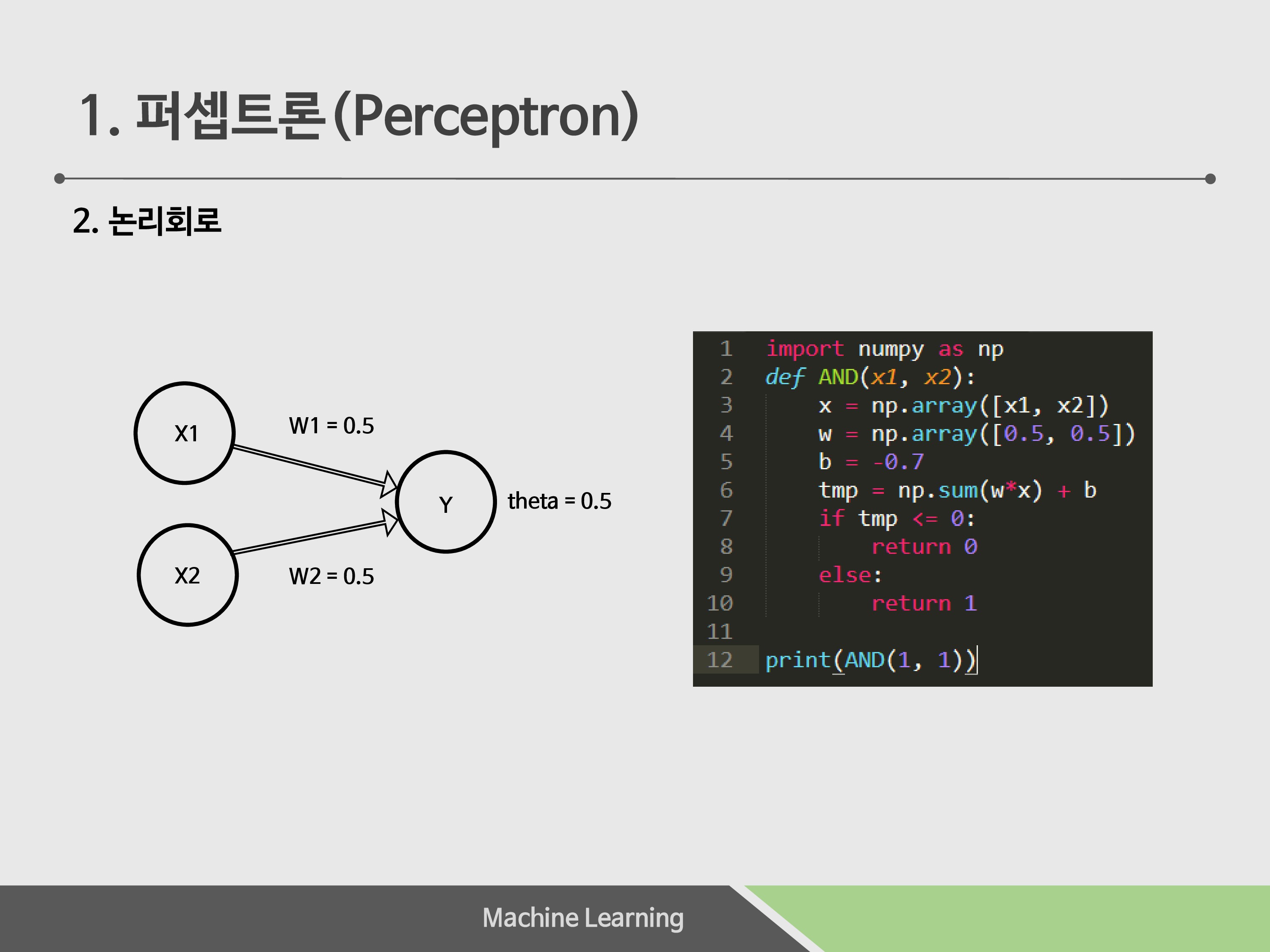
실제로 파이썬 코드로 구현을 해 보았습니다. Numpy 라이브러리를 통해 행렬을 구현해서 간단하게 게이트를 만들어 보았습니다.
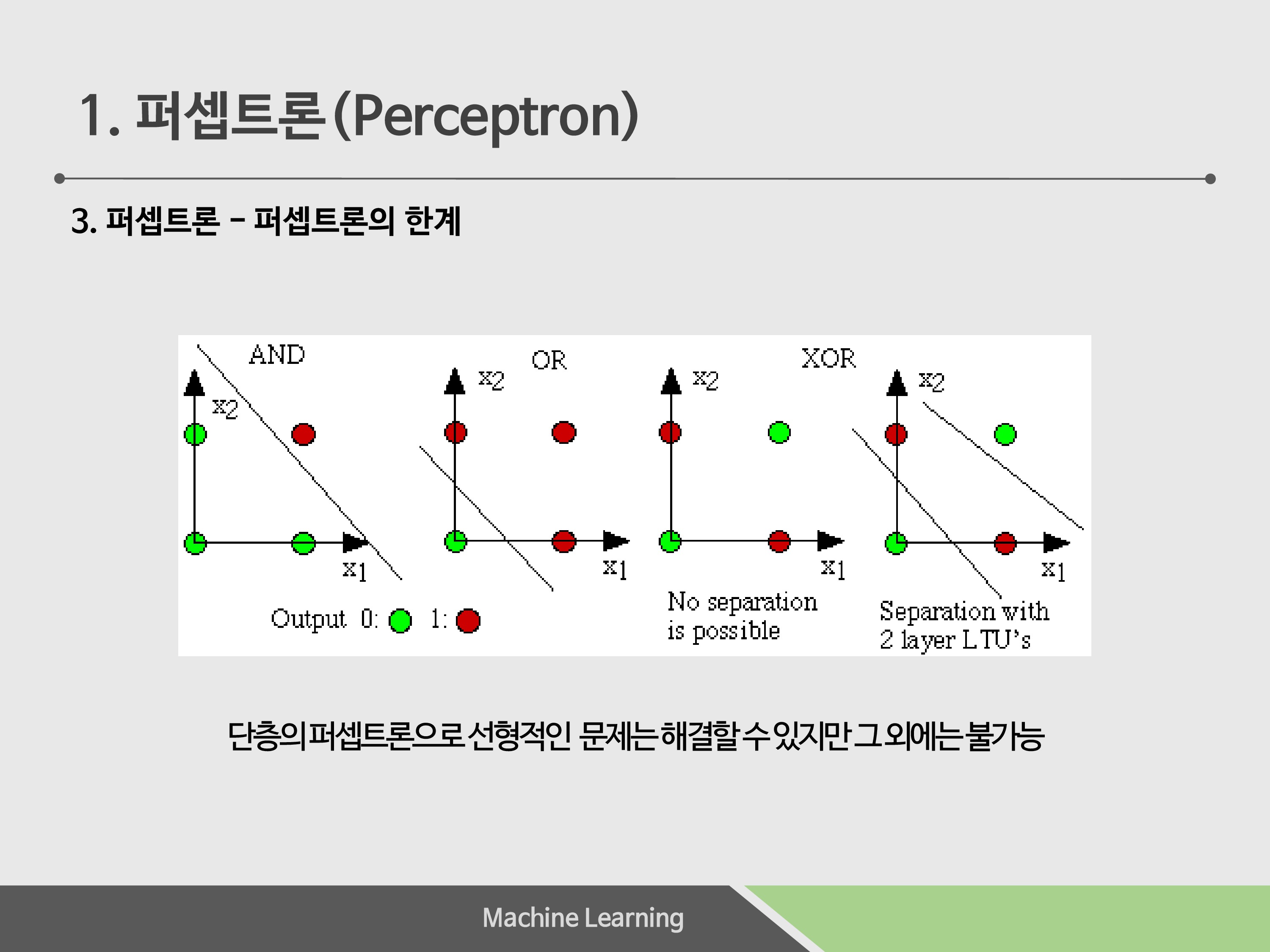
X1*W1 + X2*W2 = theta
의 식을 확인해보면, 하나의 선형적인 그래프가 나온다는 것을 확인할 수 있습니다. 이렇게 되면 XOR의 결과값은 그림을 볼 때, 하나의 선으로 분류할 수 없는 한계를 확인 할 수 있습니다.
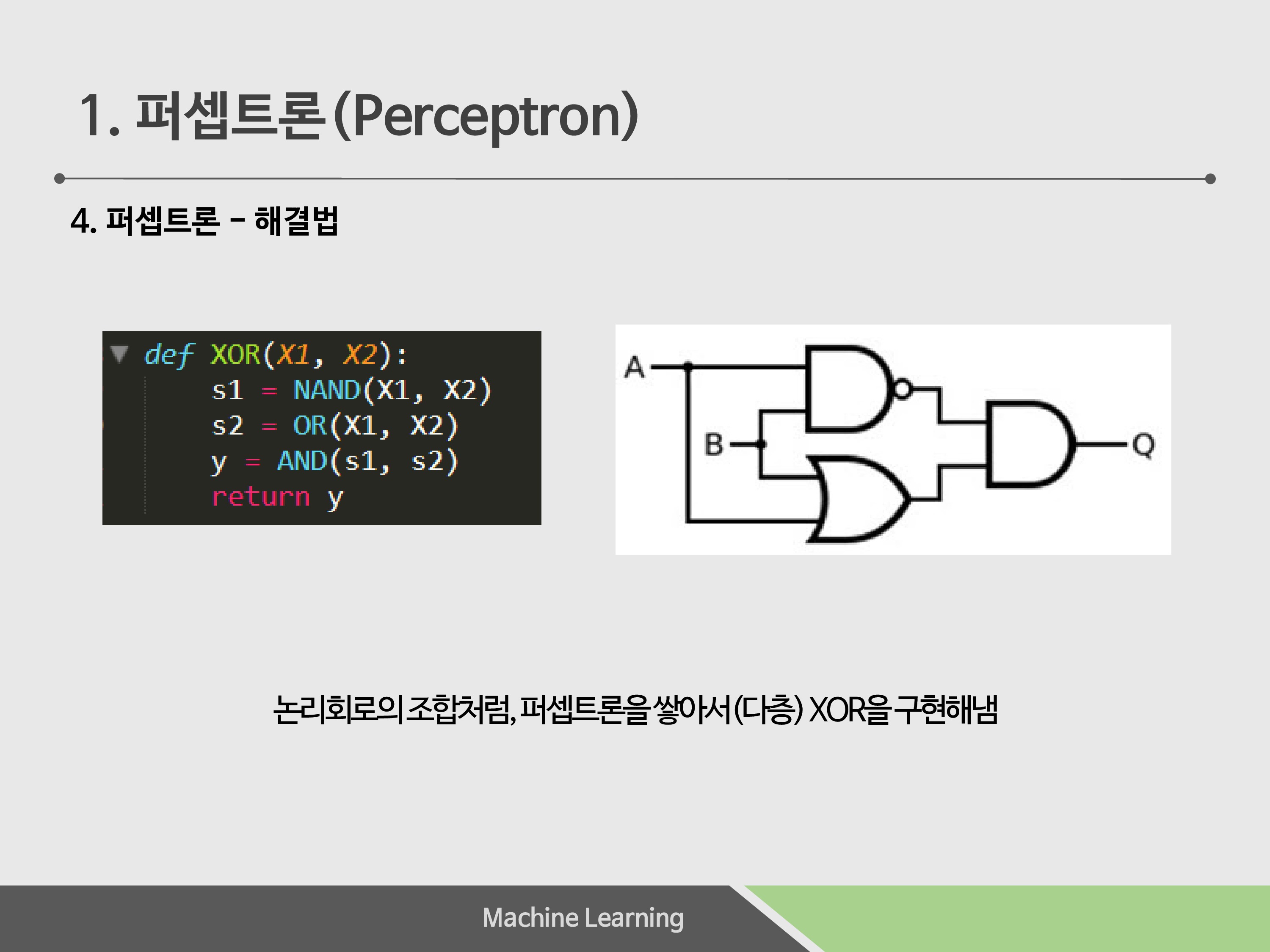
단층의 퍼셉트론으론 XOR을 구현할 수 없었습니다. 그래서 나온 해답이 ‘퍼셉트론을 쌓는다’ 입니다. AND, OR, NAND를 조합하게 되면 XOR을 구현 가능함을 확인하실 수 있습니다.

신경망도 퍼셉트론과 공통점이 많습니다. 인공뉴런(퍼셉트론)을 결합한 것이 신경망입니다.
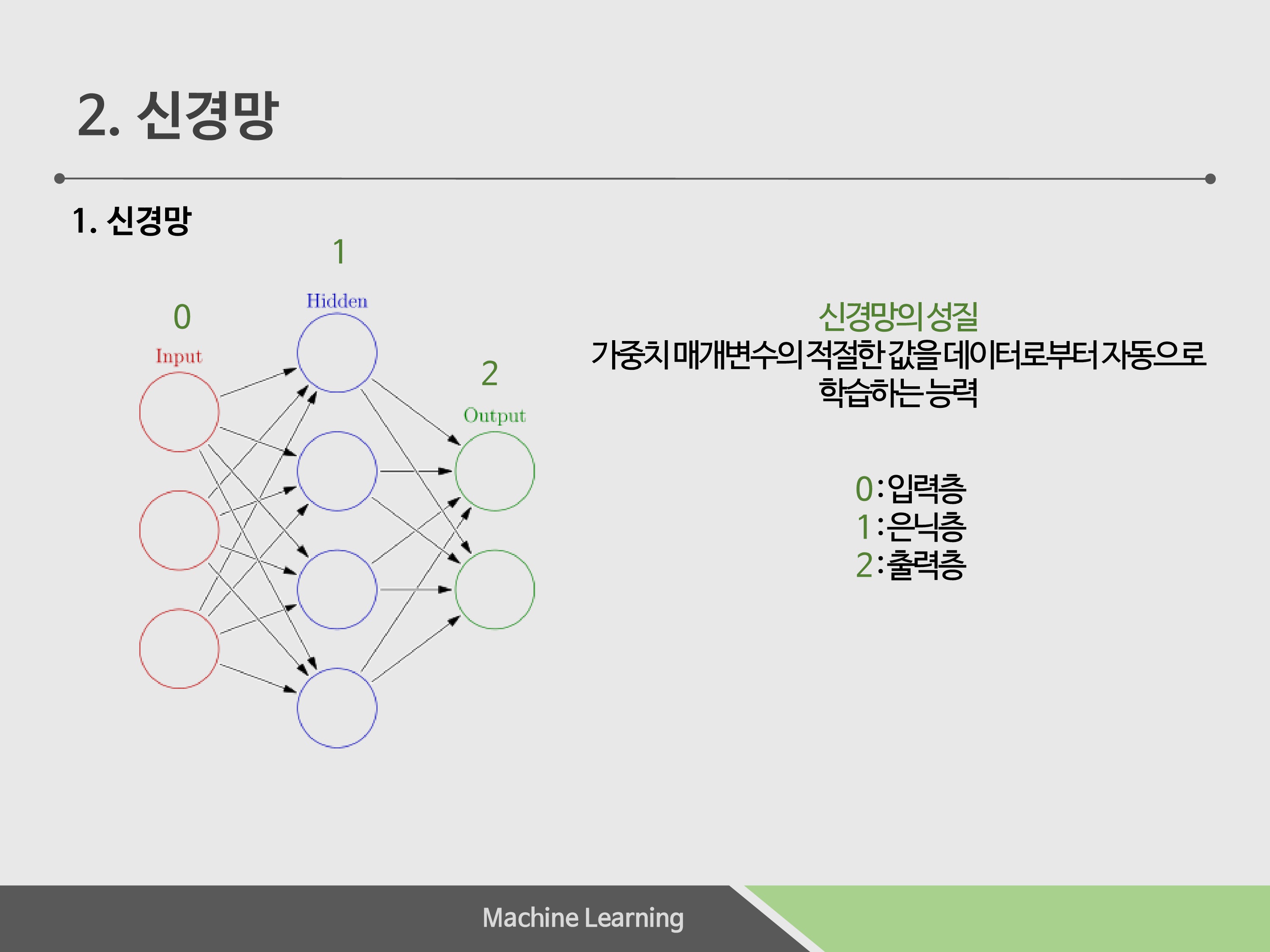
신경망의 구성은 3개입니다. 인덱스가 0부터 시작하므로, 0층부터 시작했습니다. 입력층, 은닉층, 출력층으로 구성되어 있고, 은닉층의 뉴런은 사람들 눈에는 보이지 않으므로 은닉층이라는 이름이 붙여졌다고 합니다.
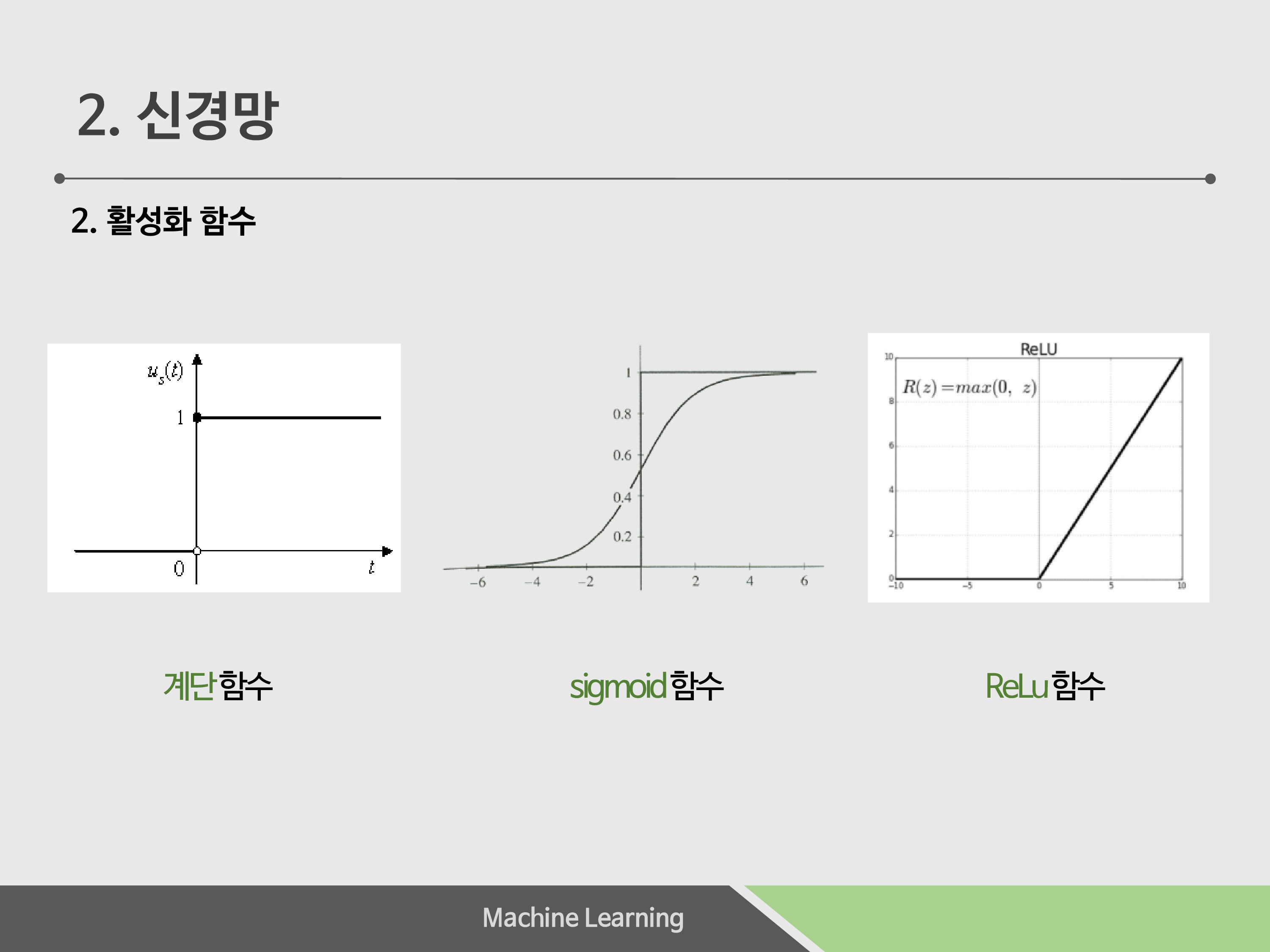
활성화함수의 종류입니다. 앞에서는 편의를 위해 계단함수로 가정하고 진행했지만 여러 활성화함수가 있습니다. 자세한 함수의 설명은 4, 5단원의 개념이 있어야 정확히 알 수 있으므로 간략하게 설명하겠습니다.
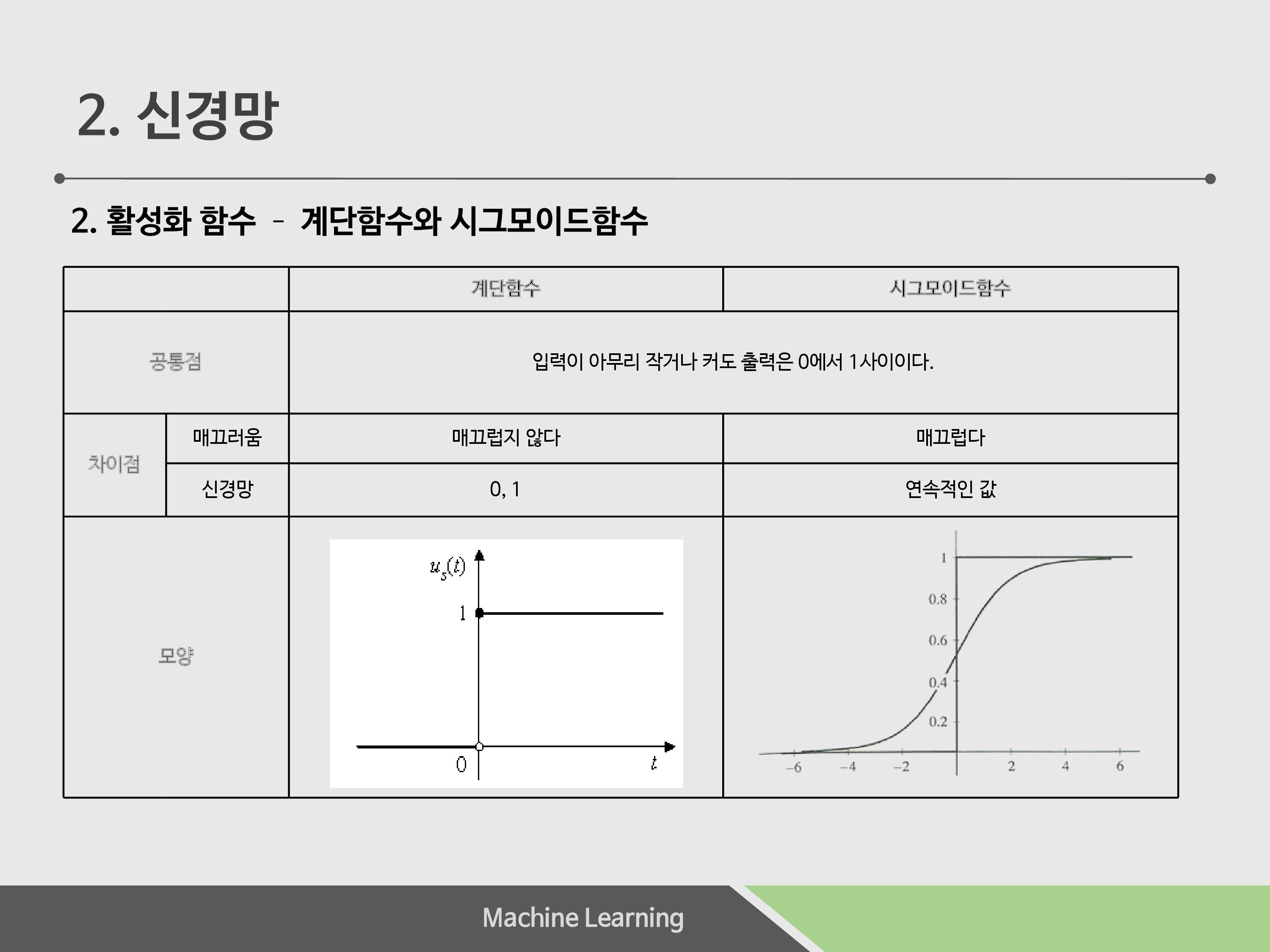
주로 우리는 계단함수보다 시그모이드 함수를 사용합니다. 0 or 1만 출력하는 계단함수와는 달리 연속적인 값을 출력하고, 좀 더 ‘인간스러운’ 생각을 하려면 확률을 이용해야 하므로 0, 1 보다는 연속적인 값을 통해 맞다, 아니다의 확률을 출력시킬 수 있는 시그모이드 함수가 좀 더 신경망에 좋습니다.
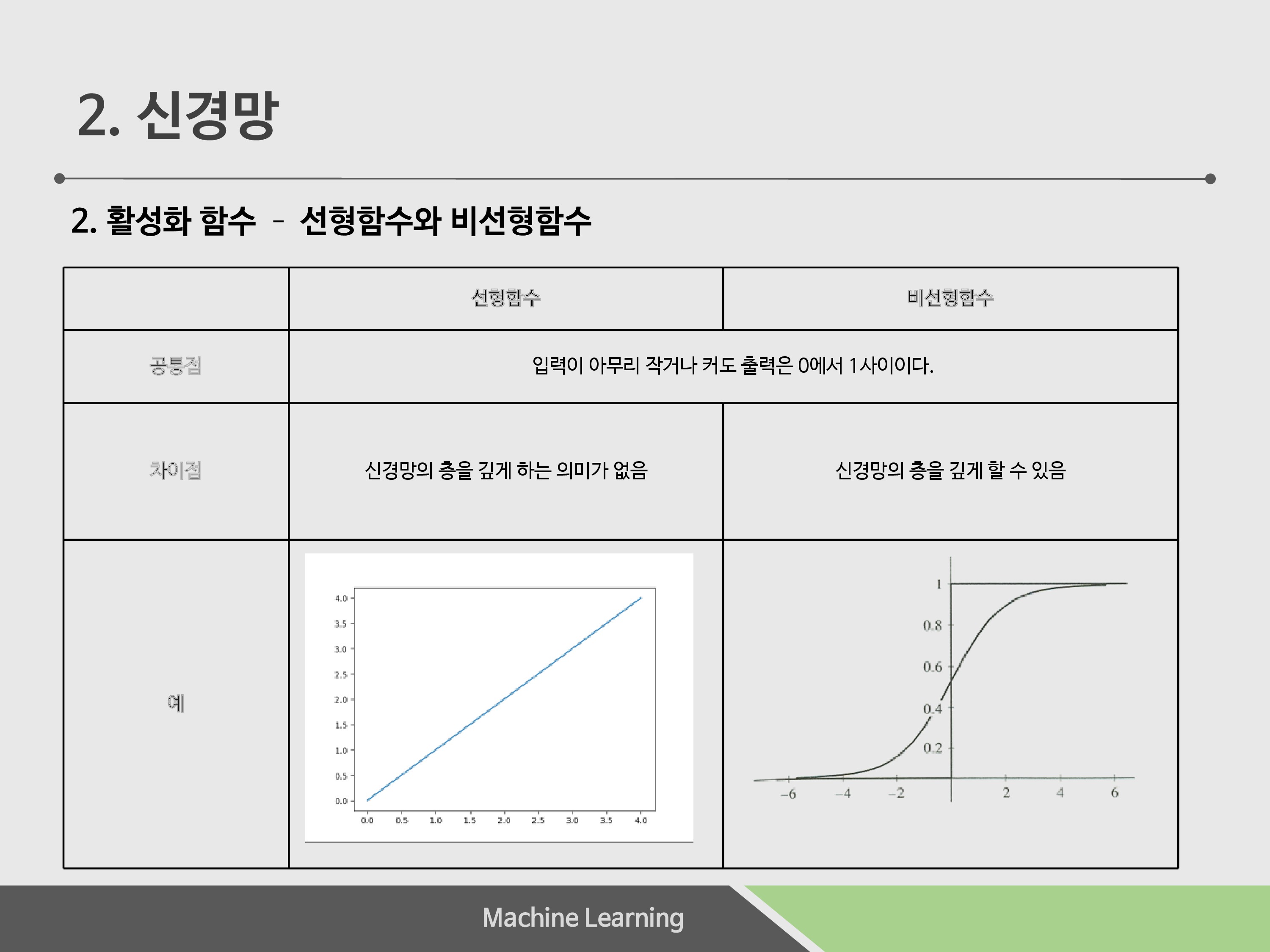
그럼 연속적인 값을 출력시킬 수 있는 선형함수를 써도 좋지 않은가 하는 생각을 할 수도 있지만, 선형함수의 경우엔 신경망의 층을 깊게 하는 의미가 없어지기 때문입니다.
H(X) = cX라는 식을 활성화함수로 가정한다면, 이 활성화 함수로 3층 신경망을 구현한다 가정하면, y(X) = h(h(h(x)))가 되고, 이는 y(X) = c*c*c*x가 되는데, 이 함수는 y = ax와 크게 다르지 않은 식이 되버리고 맙니다. 이처럼 층을 쌓는 의미가 없어져서 선형함수는 사용하지 않습니다.
ReLu 함수는 5단원의 오차역전파법에서 자세히 설명이 되 있으니 여기서 설명하지 않겠습니다.
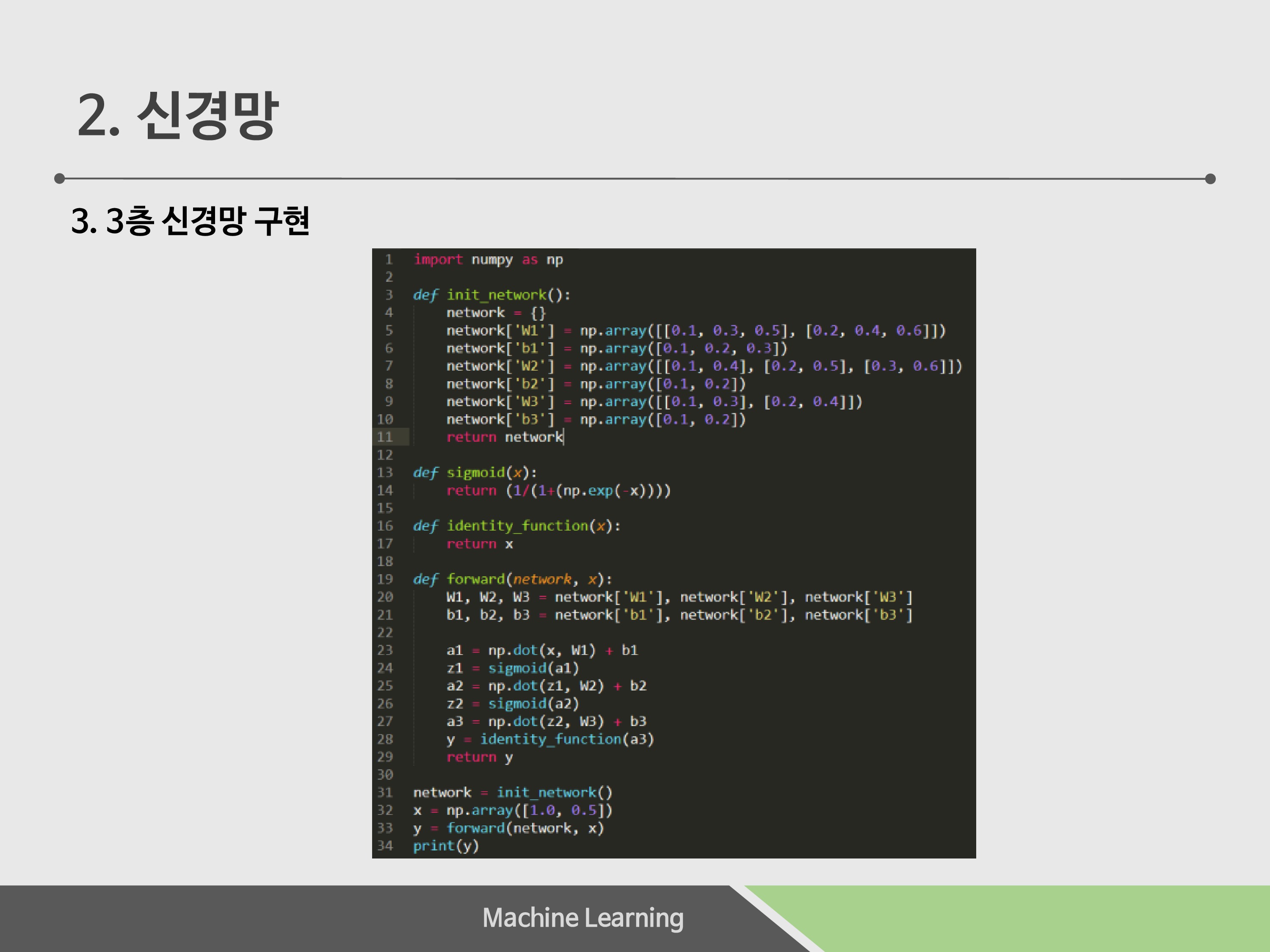 3층 신경망을 직접 구현해 보았습니다.
3층 신경망을 직접 구현해 보았습니다.
코드는책 83~93p과동일한코드입니다. W1, W2, W3는각층의가중치, b1, b2, b3는편향입니다.
Dot 연산은 행렬의 내적계산입니다.
19번째 줄부터 찬찬히 살펴보면, 입력층을 내적 후 bias를 더하고, sigmoid function을 거치게 됩니다. 이 것을 3층 동안 반복하는 것을 확인 할 수 있습니다. 직접 사람의 눈에 보이지 않으니 3층동안 반복하는 연산은 은닉층이 됩니다.
32번째 줄 x는 입력, y는 계산 과정을 거친 출력값입니다.

회귀분석에선 항등함수를 이용하지만, 확률이 필요한 분류에서는 Softmax함수를 이용합니다.
항등함수는 다들 아시리라 생각하므로 설명은 생략하겠습니다. Softmax는 뉴런의 출력값을 정규화시켜 ‘확률’로서 출력시켜주는 함수입니다.
Softmax의 식은 윗 값과 같이 입력층의 지수함수/모든 신호의 지수함수의 합으로 이루어져 있습니다.

특징은 슬라이드에 설명되어 있습니다. 주로 분류에서 사용되고, 출력층의 총 합은 1입니다.
Softmax 함수는 단조증가함수라, 원소들의 대소관계는 변하지 않습니다.
즉, Softmax함수를 쓰나, 안 쓰나 누가 더 큰지, 누가 더 작은지 관계에 대해서는 변하지 않습니다.
출력시에는 분류에선 특정값이 ‘정답’이다만 출력시킬 수 있으면 되기 때문에 Softmax는 필요하지 않습니다만, 학습 중에는 Softmax 함수를 거쳐서 진행해야 합니다.
이에 관련한 내용은 4장에 나와 있습니다.